Ever wanted to build powerful AI agents without paying for API calls or sending your private data to a third party? What if you could run a complete automation and AI stack right on your laptop?
In this guide, I’ll walk through deploying the powerful workflow automation tool n8n and connecting it to a local Large Language Model (LLM) using the intuitive and open-source Podman Desktop.
By the end of this post, you’ll have a fully functional, private, and free-to-run AI agent setup, ready to automate tasks, generate content, or power your next big idea.
What We’ll Build
We will create a single Podman Pod to serve as a shared environment for our two containers. This is the key to allowing them to communicate seamlessly. The pod will contain:
- n8n: The low-code automation platform that will be our agent’s “nervous system.”
- Ramalama Model Server: RamaLama is an open-source tool that simplifies the local use and serving of AI models. This will act as our agent’s “brain.”
Part 1: Deploying Our Services in a Shared Pod
Let’s build our stack, we are using a single Pod to host both containers, ensuring both services can talk to each other from the start.
Step 1: Install Podman Desktop
If you haven’t already, download and install Podman Desktop from the official website. On first launch, follow the prompts to initialize and start the Podman machine.
Step 2: Prepare for the shared Pod Deployment
A Pod is the smallest deployable unit in Kubernetes and Podman. A Pod can contain one or more containers that run together on the same host, share the same network, and can share storage volumes.
In Podman Desktop, you have the possibility to create separate containers but we want to create a shared Pod to have the 2 main containers.
To prepare for the Pod deployment, we’ll first pull the needed images:
Editor is now accessible via:
http://localhost:5678
Press "o" to open in Browser.- In Podman Desktop, navigate to Images, click Pull an image, and pull docker.io/n8nio/n8n
- Again, click Pull an image, and pull quay.io/ramalama/ramalama-llama-server@sha256\
:3ca009ed7c1bf97c79f1f8314117dc\
3f1eced88c8fcfe8b216797bef84b6e440 - Once pulled, let’s test first the n8n deployment. Find the n8nio/n8n image and click the Run (▶️) button.
- The Create a container screen will appear. Configure the following:
- Container Name: n8n-instance.
- Volume Mappings: Map the n8n_data folder from your host to the container path /home/node/.n8n.
- Port Mapping: Click + and map Host Port 5678 to Pod Port 5678 (for n8n).
- Environment Variables: Add a variable with the Name GENERIC_TIMEZONE and the Value of your timezone (e.g., America/New_York or Europe/Berlin).
- In the Advanced tab, under “Specify user to run container as:” enter root , to avoid any previlages errors.
- It should look something like this:
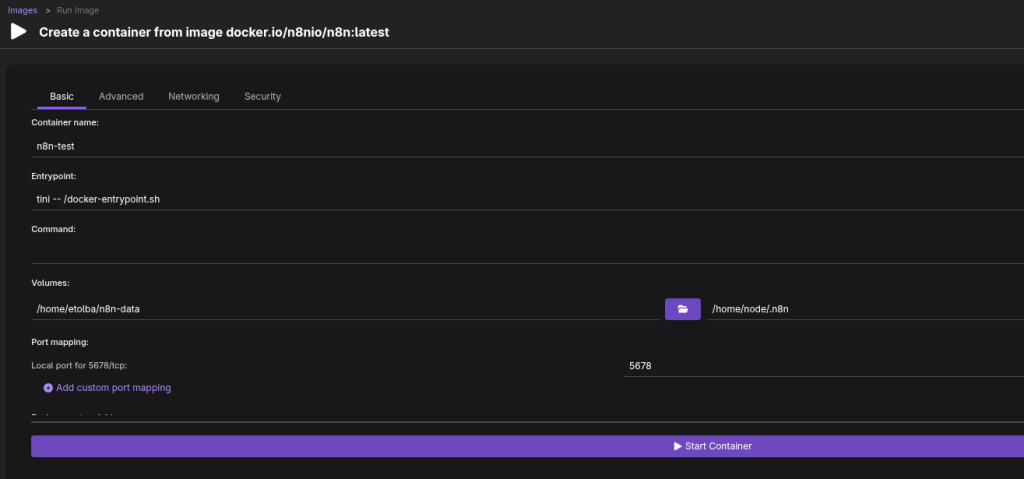
- Click Start Container. This will create the Pod and launch n8n inside it, you’ll be taken to the container terminal showing the container creation.
- In few seconds, the conatiner will be created and you’ll see this message:
Editor is now accessible via:
http://localhost:5678
Press "o" to open in Browser.In your browser address bar, go to: http://localhost:5678 and you should see the n8n login/singup page.
Now we have a working n8n instance deployed locally using Podman desktop were many automation workflows can be created and used. But our main goal is to have an AI agent in the n8n workflow so let’s delete the created container and continue the deployment of the shared Pod, including n8n & Ramalama containers.
To delete the container:
- In Podman Desktop, navigate to Containers, you’ll find the running container “n8n-instance“
- On the right-hand side, click the delete icon to delete the container
Step 3: Download the Large Language Model
Now we need to download a LLM to use for our AI agent locally on our machine. This can be done through Podmand Desktop with the included AI Lab extension.
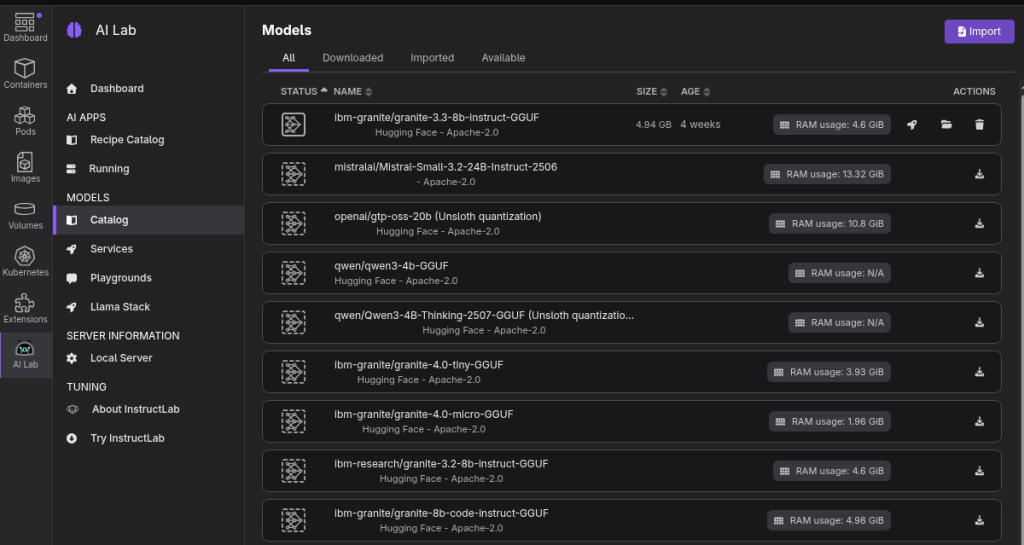
- In Podman Desktop, navigate to Extensions then Catalog tab and install Podman AI Lab extension.
- Once installed, you’ll find in the left menu a new item “AI Lab” from there, navigate to Models > Catalog and choose a GGUF model to download from the list of avaialbe models.
- In my testing, I can say the granite-3.3-8b model is enough for such a use case, but here we have the flexibility to test different models and get different results depending on your use case.
- Once the model is downloaded, copy the model name (in my case granite-3.3-8b-instruct-Q4_K_M.gguf) and click on the folder icon to get the model’s local full path (in my case /home/<user>/.local/share/containers/\
podman-desktop/extensions-storage/redhat.ai-lab/\
models/hf.ibm-granite.granite-3.3-8b-instruct-GGUF/\
granite-3.3-8b-instruct-Q4_K_M.gguf ) and copy it to be used later in the YAML file.
Step 4: Prepare the YAML file for the shared Pod deployment
In Podman Desktop, you can create Pods using Podman Kube Play, where you can import a YAML file or enter YAML directly in Podman Desktop interface.
I’ll go through each part of the YAML file and then provide the full YAML file to use directly in Kube Play.
Root
This YAML file defines a single Pod named n8n-ai-pod that groups two containers to run as a single application.
apiVersion: v1
kind: Pod
metadata:
name: n8n-ai-pod
spec:
...Containers
This section lists the two services that will run inside the Pod:
- n8n-container: This runs the n8n automation platform using its official image. It exposes the n8n web interface by mapping port 5678 on your host to the container. It also uses a volume to save its data.
- ai-model-container: This runs the ramalama AI server to serve an LLM. It exposes the AI’s API by mapping port 8080 on your host to the container. It uses environment variables for configuration and a volume to load the model file.
containers:
- name: n8n-container
image: docker.io/n8nio/n8n
ports:
- hostPort: 5678
volumeMounts:
- name: n8n-data-volume
...
- name: ai-model-container
image: quay.io/ramalama/ramalama-llama-server
ports:
- hostPort: 8080
volumeMounts:
- name: ai-model-file-volume
...Volumes
This section defines the storage that the containers use. It links storage from your host machine into the Pod.
- n8n-data-volume: This provides persistent storage for n8n. It connects the container’s internal data path to a directory on your host, ensuring your workflows are saved.
- ai-model-file-volume: This provides the AI model file to the ramalama server. It takes the GGUF file from your host machine (Model folder from Step 3) and mounts it inside the AI container, allowing the server to load it.
volumes:
- name: n8n-data-volume
persistentVolumeClaim:
claimName: n8n-data-storage
- name: ai-model-file-volume
hostPath:
path: <Model path>
type: FileThe Full YAML
You’ll need to edit some variables (highlighted below in the file) to match your deployment.
apiVersion: v1
kind: Pod
metadata:
name: n8n-ai-pod
spec:
containers:
# ---- 1. n8n Container Definition ----
- name: n8n-container
image: docker.io/n8nio/n8n
ports:
- containerPort: 5678
hostPort: 5678
env:
- name: GENERIC_TIMEZONE
value: "Europe/Berlin" <<<<<<<<<<<<Enter your timezone
volumeMounts:
- name: n8n-data-volume
mountPath: /home/node/.n8n
securityContext:
runAsUser: 0
# ---- 2. AI Model Container Definition ----
- name: ai-model-container
image: quay.io/ramalama/ramalama-llama-server@sha256:3ca009ed7c1bf97c79f1f8314117dc3f1eced88c8fcfe8b216797bef84b6e440
ports:
- containerPort: 8000
hostPort: 8080
env:
- name: HOST
value: "0.0.0.0"
- name: PORT
value: "8000"
- name: MODEL_JINJA
value: "true"
- name: MODEL_PATH
value: /models/<model name> <<<<<<<<<<<<Enter your model name
volumeMounts:
- name: ai-model-file-volume
mountPath: /models/<model name> <<<<<<<<<<<<Enter your model name
# ---- Volume Definitions ----
volumes:
- name: n8n-data-volume
persistentVolumeClaim:
claimName: n8n-data-storage
- name: ai-model-file-volume
hostPath:
path: <Model path> <<<<<<<<<<<<Enter your local model folder path from Step3
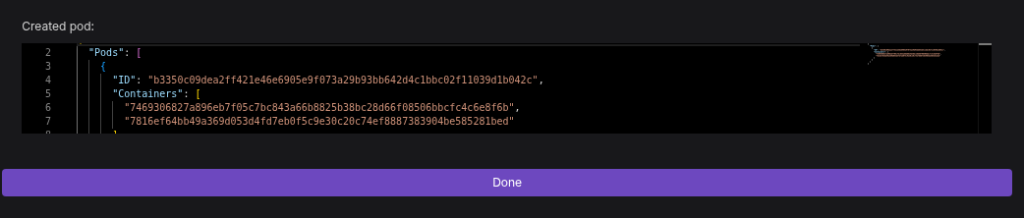
type: FileOnce your YAML file is ready with the correct variables, In Podman Desktop, navigate to Pods, then click on “Podman Kube Play“, select “Create file from scratch”, paste your full YAML file, and then click “Play Custom YAML“
You’ll get the output of the created Pod with the 2 containers.
Step 5: Verify Both Services are Running
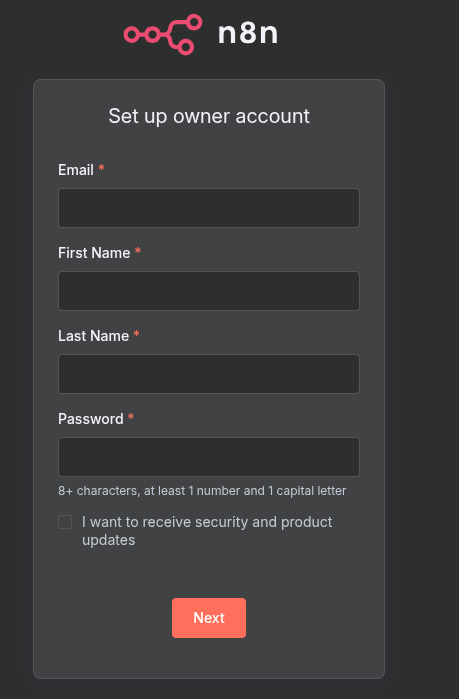
- Open your browser and go to http://localhost:5678. You should see the n8n setup screen. Create your admin account.
- Open a new browser tab and go to http://localhost:8080/v1/models. You should see a JSON response confirming the AI model is loaded and ready.

Part 2: Connecting n8n to Your Local AI Brain
With both services running in the same pod, connecting them is simple.
- Go to your n8n canvas (http://localhost:5678).
- Create a new account, in the next prompt select “I’m not using n8n for work”, once you access n8n you’ll get a prompt to put your email, and you’ll get a free license key to enable the premium features for your self-hosted n8n instance.
- Create a new workflow and add the OpenAI Chat Model node.
- Credential: Click to create a new credential. The API key doesn’t matter for local services, so enter any dummy text like local-key.
- Connection Options:
- Toggle on Use Custom OpenAI-Compatible API.
- In the Base URL field, enter: http://127.0.0.1:8000/v1
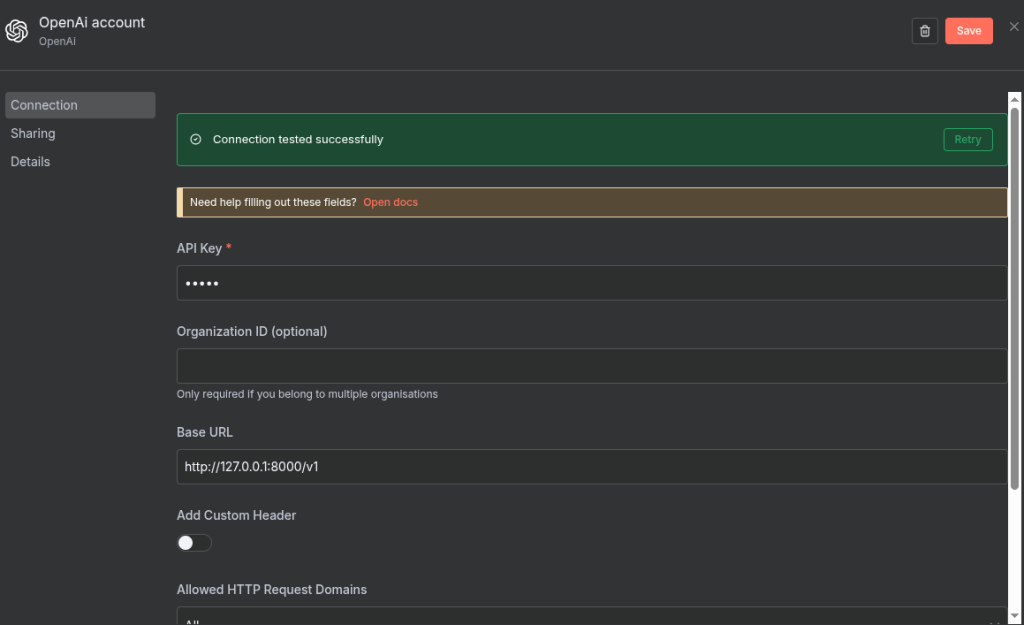
- After creating the credential, choose your model from the list
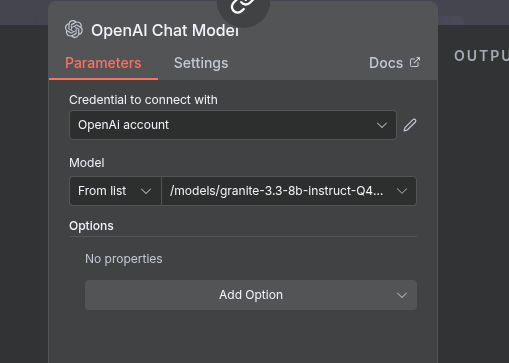
Give it a test prompt like “Tell me a joke about automation” and execute the node. You should see a response from your local LLM!
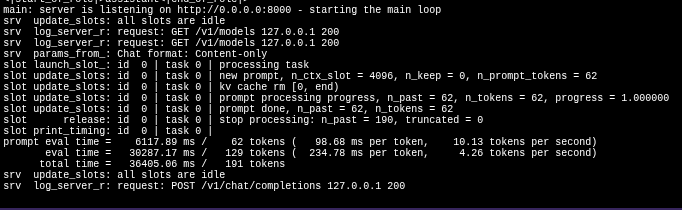
You’ll see the request going to the LLM and a response coming back (after some time given the CPU machine) and if you are interested to see what happens behind the scenes, from Podman Desktop, navigate to Containers, choose the n8n-ai-pod-model-container, then go to Logs tab and you’ll see the interaction with the model.
Part 3: Building a Simple AI Agent
With your setup up and running, you can start creating your first agent.
- In n8n Dashboard> Create new workflow
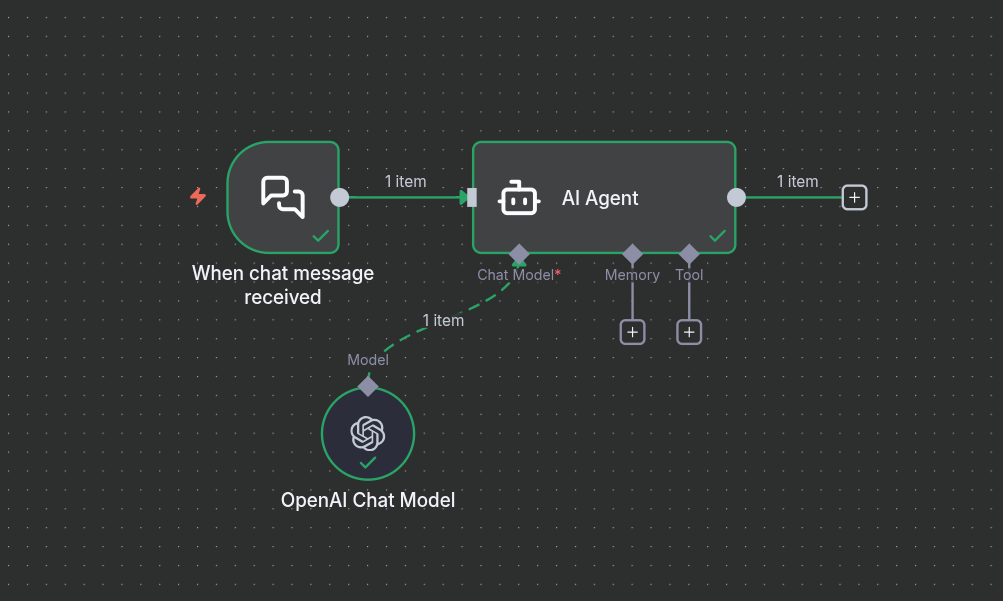
- Click on “Add first step“, and search for AI Agent
- Click on back to canvas and you’ll see that now you have:
- A chat trigger
- AI Agent with connectors (Chat Model, Memory, Tool) and an output to the next step.
- Add a Chat Model, search for OpenAI Chat Model and choose your model as shown in Part 2.
- Click on the Chat trigger and test your agent.
You’ve just created an agent that uses its local AI brain to perform a tasks.
This can then be extended by connecting memory and other tools and taking it’s output as a final output or as an input to another agent to do a series of tasks.
And from Podman desktop, you can Stop and Start your Pod as needed
Conclusion
Now you have a fully operational, private, and cost-free AI automation stack running on your laptop. By correctly using a Podman Pod to network n8n with a local LLM, you’ve unlocked a new world of possibilities.
From here, you can explore more complex agents, connect to other services, and build incredible automations—all with complete control over your data and tools. Happy building!